Course / training:Method for Logical AnalysisPrincipes van Formele logicaCombinatorische explosie in Logische systemen3. Syntactische expansie.Wanneer we semantische structuren willen vastleggen buiten onze eigen denkwereld, of overdragen aan anderen, zullen we ze eerst in een empirische vorm moeten weergeven. Dit betekent dat we 'gedachte' redeneringen uitkiezen op het semantische niveau en deze vervolgens omzetten in waarneembare of althans voorstelbare redeneervormen op het syntactische niveau. We maken hierbij gebruik van een geschikte bijbehorende logische taal, bijvoorbeeld die van de propositielogica, met bijbehorend alfabet, idioom en grammatica. Een interessante vraag is nu hoeveel unieke syntactische redeneervormen in een logisch systeem mogelijk zijn bij gegeven basisparameters voor het aantal waarden v en objecten d. Hiervoor kijken we eerst welke syntactische vormen redeneringen in het algemeen kunnen aannemen. Een aantal randvoorwaarden nemen we daarbij in acht.
(1)
Syntactische welgevormdheid.De eerste eis aan een adequate logische taal is dat ze beperkingen stelt aan de uitdrukkingsvormen bij specififeke semantische inhouden (via formatieregels). Hierdoor biedt ze eenduidige criteria om te bepalen of uitdrukkingsvormen tot die betreffende taal behoren: zgn. welgevormdheidsregels. (2) Semantische eenduidigheid.Een andere eis is ondubbelzinnigheid van interpretatie: een specifieke syntactisch vorm mag maar voor één uitleg vatbaar zijn. (3) Volledigheid.Alle mogelijke semantische inhouden (geldigheidswaarden, waarheidswaardepatronen) onder gegeven parameters { v,d}, worden elk minstens één keer in syntactische vorm afgebeeld. Vervolgens zijn er enkele eigenschappen en bijzonderheden waarmee we rekening moeten houden.
(a)
Syntactische keuzevrijheid.De semantiek van het logisch systeem gehoorzaamt louter aan logische wetten die universeel zijn, en daardoor is ze inherent (c.q. noodzakelijk) rationeel. De syntax kent echter veel meer vrijheid van expressie. Door deze 'vrijheidsgraden' zijn de keuzemogelijkheden voor syntactische vormen niet altijd gebonden aan de logische wetten, en kunnen en dus in zekere zin irrationeel zijn, of althans niet noodzakelijk rationeel. We zullen hieronder zoveel mogelijk naar de 'rationele' mogelijkheden van de syntactische vormen kijken. Soms is het echter een kwestie van het vinden van de 'minst irrationele' keuze, waarin een arbitraire component niet altijd valt uit te sluiten. (b) Uitsluiten van afunctionele doublures.Doublures zijn in het algemeen niet illegitiem in de logica en evenmin disfunctioneel. Ze zijn echter niet altijd in dezelfde mate functioneel.
Op semantisch niveau bestaan in principe geen doublures, ze zijn daar simpelweg betekenisloos.
Op de overbrugging tussen semantisch en syntactisch niveau kunnen in vrijwel elke adequate logische taal voor één en dezelfde semantische inhoud echter in principe oneindig veel verschillende syntactische uitdrukkingsvormen bestaan met dezelfde betekenis: synoniemen. Binnen dezelfde syntactische vormen kunnen vervolgens in principe ook weer oneindig veel doublures voorkomen van deelexpressies zoals atomen en subformules - slechts beperkt door de capaciteit van het medium van vastlegging. Daarbij kunnen syntactische doublures al dan niet effect hebben op de semantische inhoud (d.i. geldigheidswaarde, waarheidswaardepatroon) van de gehele constructie. Doublures die geen semantische relevantie hebben willen we hier uiteraard vermijden. 3.1.Hoofdvormen van redenering.Redeneringen zijn op syntactisch niveau te beschouwen als een reeks van één of meer al dan niet samengestelde beweringen (proposities) die gecombineerd worden en verbonden door een hoofdconnectief op de base-line van de redenering.
(1)
Redeneervormen met symmetrisch hoofdconnectief: constellaties.Een 'statische' redenering wordt gevormd door een constellatie van één of meerdere elementaire proposities, elk in willekeurige vorm, verbonden door willekeurig welke connectieven - behalve dat de implicatie voor het hoofdconnectief is uitgesloten. Hierdoor kunnen geneste relaties minstens tweeplaatsig (korter gezegd meerplaatsig) zijn.
Bijv.: '¬A
 (¬(B (¬(B 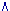 C
D) (¬E
¬F))'. C
D) (¬E
¬F))'.(2) Redeneervormen met asymmetrisch hoofdconnectief: afleidingen (derivaties).Een 'dynamische' redeneervorm is de afleiding c.q. derivatie. Deze bestaat uit minstens twee verzamelingen van elementen die als 'redeneerstappen' lineair geordend zijn, respectievelijk premisse en conclusie vormen, en verbonden zijn door de implicatie als hoofdconnectief. Voorbeelden:
(2a)
Ketenredenering: Syllogisme.Een eenvoudig voorbeeld van een afleidingsreeks is het syllogisme. In universele standaardvorm:
Bijv. (PPL): {(A
 X) , (X
C) } X) , (X
C) }
 CNF((¬A
X) (¬X C) );
(degres)(u) [(¬A C); ]
(A C) : is geldig.
Zie verder Introductie Propositielogica
(PDL) - Deel VIII, 17A.2. Ketenredenering: Syllogisme, in PPL;
(2b) en ook Introductie Predikatenlogica (PDL) - Deel VIf, H.17. Syllogisme. Tweede axioma in Frege's propositional calculus (Conditionality chain).
Bijv. (PPL): (X
Zo'n formule is altijd eenvoudig om te zetten in normaal vorm,
waardoor ze makkelijker beslisbaar wordt
(en in dit geval een sterkere waarde blijkt te hebben). In dit geval door parafrase via inverse directe
Transferente contradictie reductie. (B
C)); ((X B
) (X C)).
Bijv. (PPL): (X
(B
C)); CNF(¬X ¬B C);(¬X
(X ¬B)
C); (¬(¬X
B) (¬X
C));
((X B)
(X C)).Het onderscheid 'dynamisch' en 'statisch' is uiteraard syntactisch zinvol, vanuit het oogpunt van menselijke informatieverwerking: de eerste geeft een sequentieel en dus chronologisch proces van verwerking weer, de tweede een stand van zaken die niet gebonden is aan volgorde of tijdlijn. De eerste vorm kan uiteraard altijd in de tweede vorm worden getransformeerd, en vice versa. Tussen deze twee syntactische basisvormen bestaat op semantisch niveau dus geen wezenlijk onderscheid. Aan de bovenstaande voorbeelden van redeneringen is verder te zien dat we de variaties in redeneervorm op twee niveaus kunnen bekijken:
(a) die van 'formules' van logische relaties of proposities,
die elementen vormen in de redeneringen;
(b) en die van de omvattende structuren of 'redeneerbomen' waarin de eerstgenoemde als elementen, componenten of redeneerstappen onderling ook weer in een bepaalde logische relatie gesteld zijn. Op elk van deze niveaus kunnen we meerdere soorten van syntactische variaties onderscheiden:
•
Connectiefklasse.De klasse van het gebruikte type connectief: symmetrisch of asymmetrisch;• Het aantal basiselementenof atomaire formules;• Valentievariatie.De aanwezigheid van negatie bij basiselementen.• Volgordevariatie.De volgorde van elementen binnen de (lineaire) tekenreeks; de inbedding of 'nesting' (gecodeerd door 'haakjes' in de formule of clusters in een boomdiagram);• Connectiefvariatie.De logische relaties tussen elementen en 'nesten' (gecodeerd in specifieke connectieven).3.2.Bouwstenen (atomen).De variatie van redeneervormen wordt uiteraard allereerst bepaald door het aantal basiselementen waarmee we redeneren, de 'atomen' of 'eindelementen' die niet verder worden uitgesplitst. Tussen de basiselementen leggen we één of meer logische relaties. 3.2.1.Formules.Stel een verzameling D·*heeft een omvang (lengte) van d elementen (objecten c.q. atomen). Alle mogelijke logische relaties tussen deze elementen worden, onder de parameters {v,d}, bevat in de verzamelingT·(v, d). In de elementen vanT·(v,d) kunnen één tot d elementen uitD·*voorkomen. Deze atomen vormen 'eindelementen' (zgn. leaves) in de bijbehorende boomstructuren van die logische relaties. Het feitelijke aantal verschillende eindelementen, in deze bomen ligt tussen 1 en d .Met andere woorden:  { v, d { v, d |(d:=|D·*|)  t1 ( ( t1 ( (t[t1]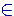 T·(v,d) )f1 ( (f[f1]
:=WFF(t[t1] ) ) n1 ( (n1 n1 ( (n1 :=|f[f1]|atm)(1 ≤n1≤d ) ) n1 )f1 )t1 }.Het probleem van doublures in elementaire formules.Het ligt voor de hand - het zou zogezegd het meest logisch zijn - om eerst de variaties op het lagere niveau, dat van de elementaire formules, te berekenen, en vervolgens die op het hogere niveau, dat van de omvattende redeneervormen. Voor de formules van logische relaties is er echter een algemene complicatie met betrekking tot het voorkomen, cq. toelaten dan wel vermijden, van doublures. Om dit te verduidelijken is voor de formules wat betreft doublures het volgende onderscheid te maken:
(a)
Functionele doublures:Semantisch functionele doublures bepalen mede de validiteitswaarde van de gehele syntactische constructie. Ze leiden dus niet tot redundantie en zijn wat dat betreft dus altijd relevant. Zo kunnen de elementaire valenties in een binair systeem, verum en falsum, worden gecodeerd door middel van dubbele vermelding van willekeurig welke atomaire formule:
Bijv. (PPL): {
Ook kunnen functionele doublures ontstaan door herdefinitie van bepaalde connectieven:$1(A
¬A ) }; {$0(
A ¬A ) }.
Bijv. (PPL): {(A
Functionele doublures kunnen verder ontstaan via verspreiding (distributie) van basale termen/
literalen. B )
((A B ) (¬A
¬B ) ); etc. };{(A #B )((¬A
B ) (A
¬B ) ); etc. };
Bijv. (PPL): (B
(C D
) ): compacte vorm, zonder doublures;Parafrase expansie, via distributie: (distr.)((B C ) (B
D ) ): 'functionele' doublures.
NB. Deze doublures kunnen anderzijds worden geëlimineerd door samentrekking (comprimatie) van complexe
termen; wegens (partiële) 'Symmetrische equivalentie' (vorm I)).
(b) Afunctionele doublures:Semantisch afunctionele doublures dragen niets bij aan de betekenis of waarde van de formule Ze hebben dus semantisch geen functie, zijn zonder meer een vorm van overtolligheid (redundantie), en zijn in dat opzicht irrelevant. Ze doen bovendien afbreuk zuinigheid en doelmatigheid van verwerking. Afunctionele doublures, kunnen globaal op twee manieren ontstaan:
(b1) Door herhaling, via parafrase expansie:
Bijv. (PPL): {A }
Te elimineren door simpele weghaling (deletie).(A
A );{A } (A A ).
(b2) Of via degressief expansie:
Bijv. (PPL): {A, B }
Te elimineren wegens transferentie equivalentie.degres((A B ) A ).
Bij het berekenen van de syntactische variaties van formules is het dus op zich geen probleem wanneer deze functionele doublures bevatten. Daarbij blijkt dat functionele doublures in syntactische weergaven van logische relaties niet altijd te vermijden zijn. Dat is al te zien bij d =3 in bijvoorbeeld:
Bijv. (PPL):
Lastig wordt het wanneer we van alle formules alle parafrasen c.q. synoniemen met functionele
doublures willen meenemen.{ ((A (B
C ) ) (C
(A B ) ) )
((A
B ) (A C )
(B C ) ) }.Bij d =3 levert dit al een aardige uitbreiding van het aantal varianten:
Bijv. (PPL):
Bij d { (A (B
C ) )
((A B )
(A C ) );(B (A
C ) )
((B A )
(B C ) );(C (A
B ) )
((C A )
(C B ) ) }.(4 atomen, waarvan 1 dubbele). Maar ook: { ((A (B
C ) ) (C
(A B ) ) )
((A
B ) (A C )
(B C ) );((B (A
C ) ) (C
(A B ) ) )
((B
A ) (B C )
(A C ) );((C (A
B ) ) (B
(A C ) ) )
((C
A ) (C B )
(A B ) ) }.(6 atomen, waarvan 3 dubbelen). =4:
Bijv. (PPL):
Zoals te zien is aan deze voorbeelden leidt het uitputtend insluiten van alle synoniemen met functionele
doublures al heel snel tot een nieuwe, extreme combinatorische explosie. Alleen al voor het geval van a
{ (A (B
C D ) )
((A
B ) (A C )
(A D ) );.. { ((A (B
C D ) )
((B (A
C D ) )
((C (A
B D ) )
((D (A
B C ) ) )
((A B ) (A
C ) (A
D ) (B
C ) (B
D ) (C
D ) ) }.(12 atomen, waarvan 8 dubbelen). =4 zijn vele bladzijden te vullen met varianten nog voordat we aan de overige variaties toekomen.De eerste uitdaging bij berekening van syntactische variatie is semantische volledigheid: om met een bepaalde methode van formuleconstructie te garanderen dat alle validiteitswaarden (waarheidswaardepatronen) onder {v,d} - dus alle unieke logische relaties - zijn weergegeven. Een simpele methode hiervoor is om gewoon de binaire codes te gebruiken. Problematisch wordt het wanneer we voor de formules ook syntactische volledigheid willen. Hiervoor blijkt elke methode al gauw hetzij extreem bewerkelijk en tijdrovend, hetzij arbitrair en onvolledig. Om deze redenen kiezen we hier voor een andere aanpak. We nemen voor de formules hier simpelweg, omwille van de haalbaarheid, cq. om overdaad te vermijden, de logische relaties van T·(v,d) in één specifieke standaard vorm.We kunnen hiervoor de binaire codes gebruiken, of de formules in hun meest gangbare, c.q. voor de hand liggende, syntactische vorm met de connectieven {¬, , }; eventueel aangevuld met {
, #}.Voorbeeld.(Zie ook: 3.2. Axioma's voor de propositielogica). (T·(v=2,d=2)=
{ ,'( A
A)' ,'( A
¬A)' ,' A' ,' B' ,'¬A' ,'¬B','( A B)' ,'( A
¬B)' ,'(¬A B)' ,'(¬A
¬B)','( A B)' ,'( A
¬B)' ,'(¬A B)' ,'(¬A
¬B)','( A B)' ='((A B ) (¬A
¬B ) )' ,'( A #B)'='((¬A B ) (A
¬B ) )' }.Hieronder zullen we de principes van variatie voor de redeneervormen behandelen. Deze gelden mutatis mutandis ook voor de formules. Wie de volledige syntactische variatie voor de formules wil berekenen kan dus desgewenst van dezelfde principes gebruik maken (maar is met bovenstaande bedenkingen gewaarschuwd ..). 3.2.2.Redeneervormen.Eerder zagen we al (zie 2.1.6. Redeneringen, afleidingen (semantisch)) dat we een verzameling R·(v,d) kunnen definiëren als bestaand uit alle mogelijke redeneringen onder de parameters {v,d}. Ze wordt op semantisch niveau gevormd uit selecties van logische relaties vanT·(v,d), oftewel, uit deelverzamelingen vanU·(v,d).
Bijv. (PPL):
We bezien deze redeneringen nu op syntactisch niveau en (dus) voorafgaand aan parafrase-reductie.
Daarbij biedt v1 d1 (
v1 =2; d1=4;D·d1={A, B, C, D };k1 ( (U·(v,d1)[k1] U·(v,d1) );(U·(v,d1)[k1 ]={A, (¬A B ), (B
(¬C D ) ), (C
¬D ) } );CNF{A, (¬A B ), ((B ¬C )
(B D ) ), (C
¬D ) } );paraf-reduc{A, B, (C ¬D ) } ) )k1 )d1 ,
v1.U·(v,d) alle (unieke) semantische inhouden die we als bouwstenen of basiselementen kunnen gebruiken en combineren tot alle mogelijke syntactische vormen van redeneringen. De omvang van zo'n redeneervorm komt dan overeen met de 'lengte' per subset vanU·(v,d).Stel dat we voor het gemak uitgaan van heel basale parameterwaarden, v =2 (binair systeem) en d=2. Dan varieert het aantal subset lengtes, of basiselementen voor onze redeneringen (zoals we eerder zagen) binnen de range 1 tot en met t=v ^(v ^d)=16. Dit levert (zoals we eveneens eerder zagen) een power set van u
2 ^
(v ^(v ^d)) |
 '(((((¬x)
'(((((¬x)